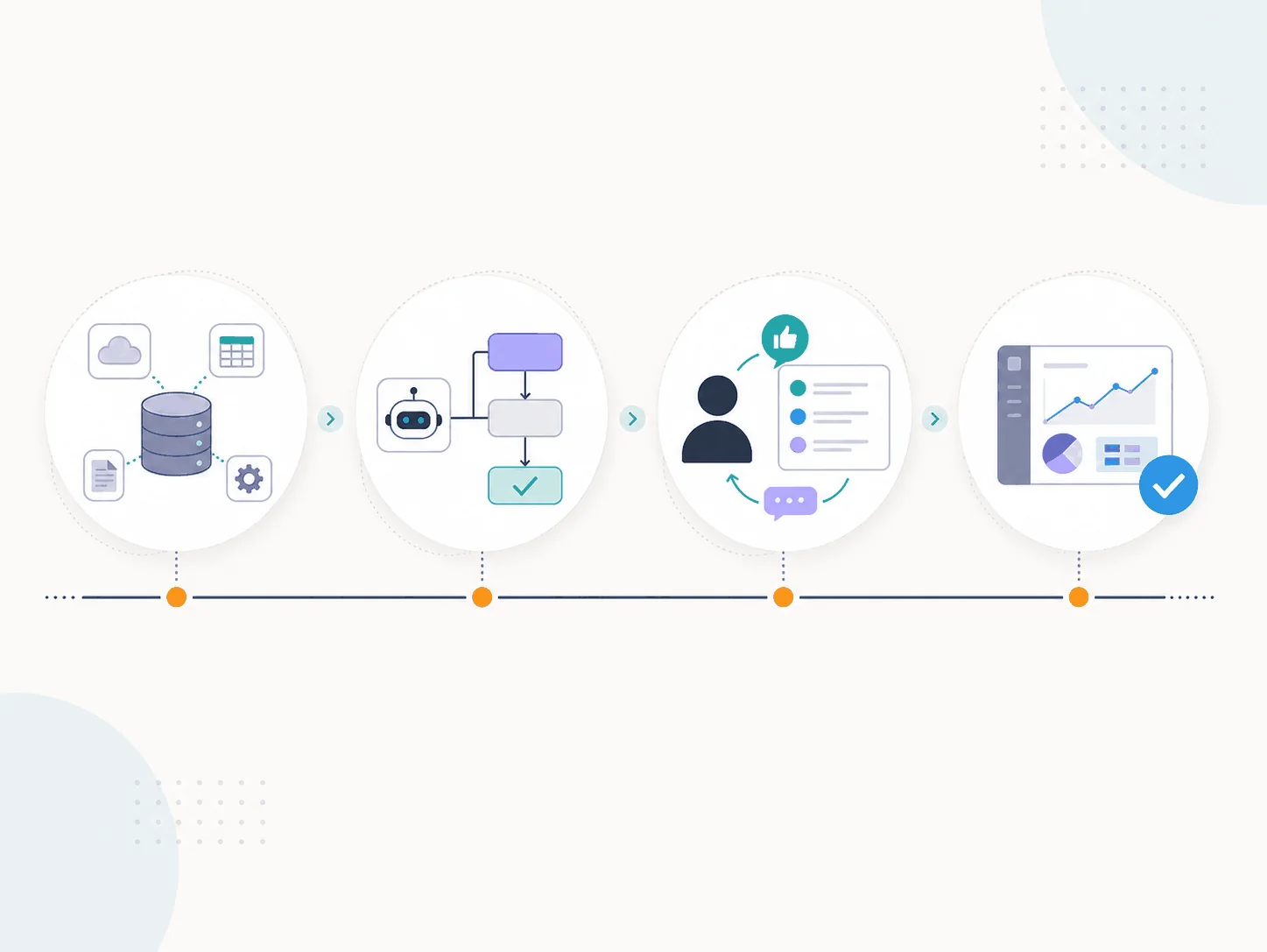
What happens during a 30-day AI agent pilot
A good pilot should not feel like a science experiment. It answers one practical question.
Many companies imagine an AI pilot as an uncertain adventure: plug in a tool, "test the AI", see what happens. That is exactly the wrong approach.
A well-run AI agent pilot answers one question, and only one: can this agent improve a real workflow — safely, clearly and measurably?
Thirty days is not enough to transform a company. But it is more than enough to prove whether a use case is real. That is precisely what a pilot is for: to settle the question.
Before day one — choose the right workflow
Everything is decided before the start. The trap is launching a pilot to "see what AI can do". Too broad, impossible to measure.
A good pilot starts from a specific workflow. Not "an AI assistant for customer service", but something like: "an AI voice agent that answers missed calls, collects the reason for the call, and sends a summary to the sales team".
Narrow, concrete, measurable. If you cannot draw the workflow on a single page, it is too broad for a 30-day pilot.
Week 1 — define the process and the rules
The first week barely touches the technology. It clarifies the ground:
- What triggers the process?
- Who is involved, and at what point?
- What data is needed?
- What does the AI handle — and what stays human?
- What happens when the AI is unsure?
- What does success actually look like?
The week 1 deliverable is deliberately simple: a pilot map. Input → AI task → human review → output → follow-up. If that map isn't clear, the pilot won't be either.
Week 2 — connect the minimum useful data
The key word for the second week is minimum. You don't wire up the whole information system. You connect only what is needed to prove value — nothing more.
This is also the moment to face data protection head-on. A few questions are enough: what personal data will the agent process? Where is it stored? Who can access it? How long is it kept?
A fast pilot can still be a responsible pilot. The two are not in conflict — as long as you ask these questions in week 2, not afterwards.
Week 3 — test with real cases, in controlled scope
The third week puts the agent in front of reality — but without handing it full powers.
You keep a tight scope: a voice agent handles a limited category of calls, outside peak hours. A recruitment agent analyzes CVs for a single open role. The goal is not full autonomy, it is observation.
You watch specific things: does the agent understand the task? Does it ask the right questions? Does it escalate correctly when it should? And above all: does the human reviewer trust what it produces?
Edge cases will appear. That is normal — it is the point. A pilot exists precisely to discover where the agent needs extra rules and limits.
Week 4 — measure value and decide
The final week ends with evidence, not opinions. You measure what matters for the chosen use case: time saved, cases handled, missed calls reduced, CVs reviewed, error rate, number of human corrections.
And you decide. Three honest outcomes, all acceptable:
- Scale it — the value is clear, you roll it out
- Improve and retest — the promise is there but the scope or rules need to change
- Stop it — the use case doesn't hold up
Stopping is not a failure. A good pilot saves you from the wrong automation — and that is money and time saved.
The real danger: confusing novelty with value
The most common trap is not technical. It is mistaking novelty for value. An impressive demo is not a proven use case.
The best pilots are small but real: one office, one open role, one call type. And they are owned by the business team that knows the workflow — not only by IT.
The right question is never "does it work in a demo?" but "could I deploy this tomorrow, with confidence, in the real world?". Thirty days is enough to answer that. That is where BeLogic starts.